11月3日消息,今天,美團正式開源全模態模型LongCat-Flash-Omni,模型總參數量5600億,激活參數量270億。美團官方博客稱,LongCat-Flash-Omni是業界首個實現全模態覆蓋、端到端架構、大參數量高效推理于一體的開源大語言模型。
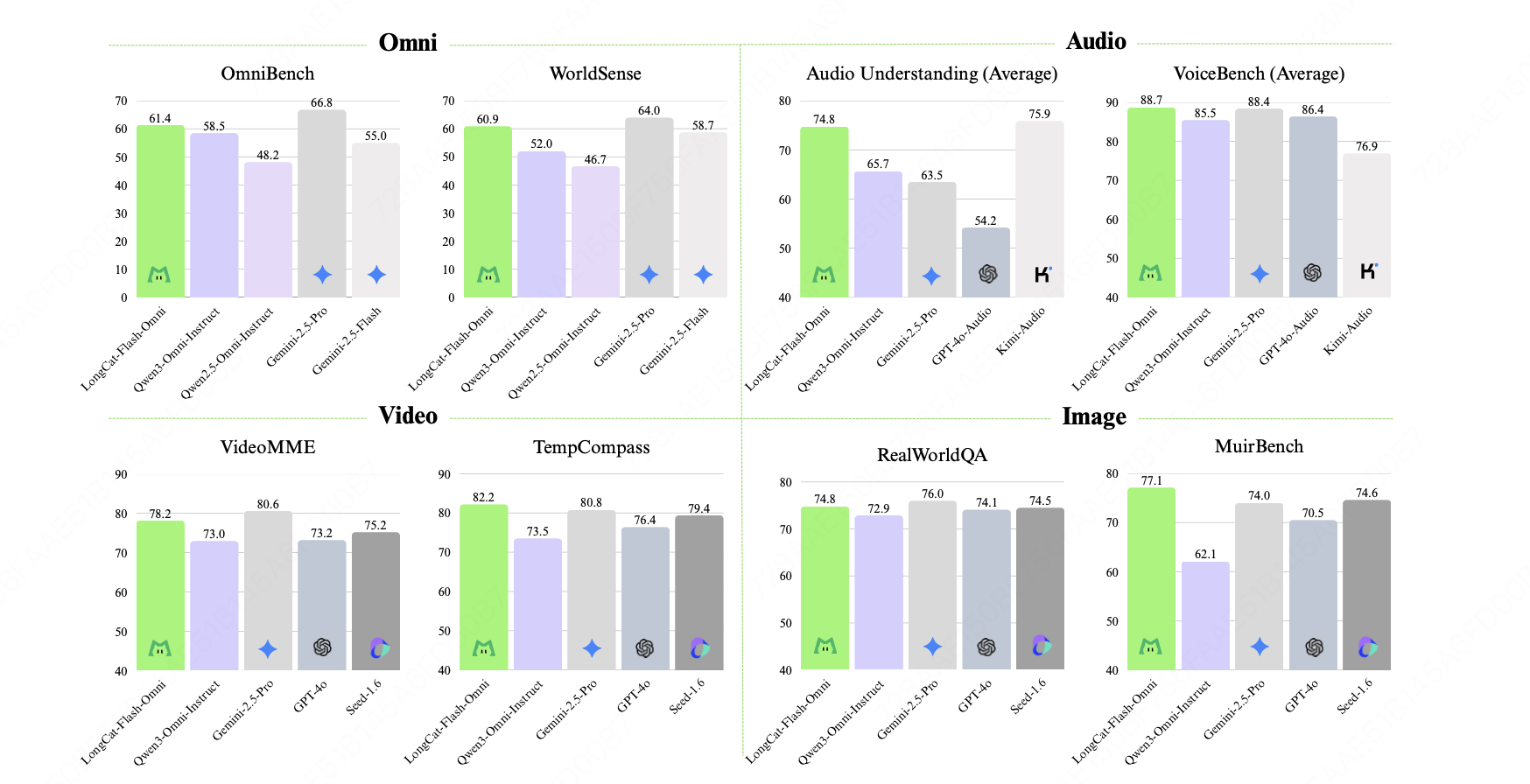
LongCat-Flash-Omni中的“Omni”譯為“全能”,其在全模態基準測試中達到開源SOTA,同時在文本、圖像、視頻理解及語音感知與生成等關鍵單模態任務中均有明顯優勢,實現“全模態不降智”。
LongCat-Flash-Omni基于LongCat-Flash構建,后者采用了高性能的Shortcut連接的混合專家(MoE)架構,并實現了零計算專家,LongCat-Flash-Omni集成了高效的多模態感知和語音重建模塊,支持128K tokens上下文窗口及超8分鐘音視頻交互。
在預訓練階段,研究人員收集了包含超過2.5萬億個詞元的大規模、多樣化的多模態語料庫用于預訓練,同時采用漸進式訓練策略,逐步從簡單的序列建模任務過渡到更復雜的序列建模任務。
這是9月1日以來,美團正式發布LongCat-Flash系列后的第三款模型,此前其已開源LongCat-Flash-Chat和LongCat-Flash-Thinking兩大版本。
值得一提的是,今天美團LongCat官方App開啟公測,目前支持聯網搜索,還可以發起語音通話,視頻通話功能后續上線。LongCat-Flash-Omni目前可以在網頁版和App端體驗音頻交互功能。
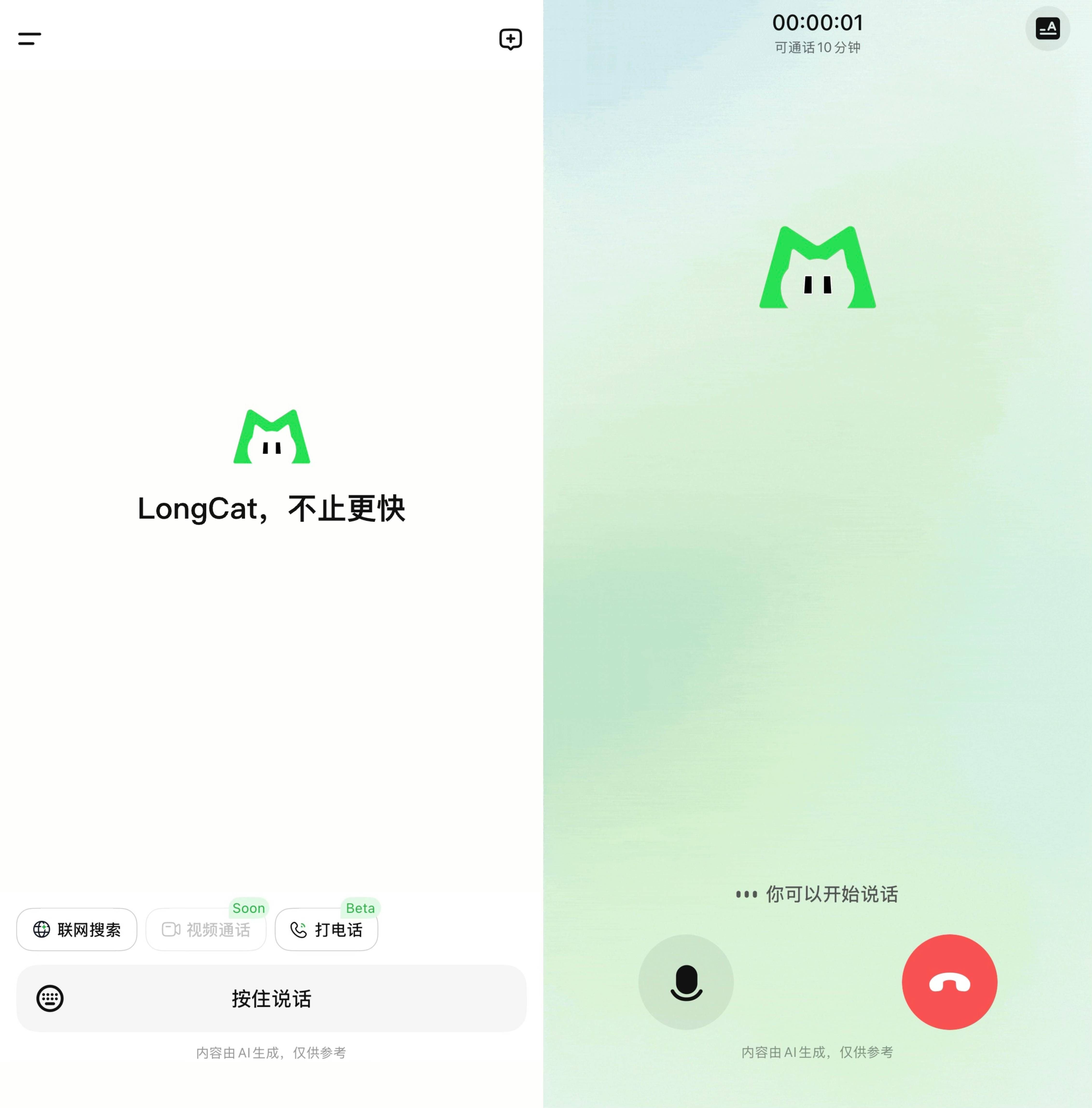
▲LongCat官方App首頁(左)、LongCat官方App音頻通話(右)
據LongCat官方交流群中的官方透露,目前LongCat的文本端模型是longcat-flash,當有多模態輸入,比如圖片和PDF內容時,會自動調用omni模型。不過智東西體驗時發現,在LongCat中上傳.jpg格式圖片時一直顯示上傳錯誤。今天中午,官方還修復了一波安卓端聯網搜索相關問題,需要安卓用戶卸載重裝。
體驗地址:https://longcat.chat/
一、視覺、音頻、文本理解生成,拿下多項開源SOTA
研究人員將LongCat-Flash-Omni與各種閉源和開源的多模態模型進行比較,包括視覺理解、音頻理解、文本理解和生成、跨模態理解以及視聽交互。其將LongCat-Flash-Omni與Gemini-2.5-Pro、GPT4o、Seed-1.6和Qwen3-Omni和視覺語言模型Qwen3-VL、Qwen2.5-VL-72B等進行了比較。
圖像轉文本方面,總體而言,LongCat-Flash-Omni的性能與Gemini-2.5-Flash相當,并且優于開源的Qwen3-Omni,其優勢在多圖像任務上尤為顯著。

視頻轉文本方面,LongCat-Flash-Omni在視頻轉文本任務上取得了最先進的性能。具體而言,它在短視頻理解方面顯著優于所有對比模型,在長視頻任務上,LongCat-Flash-Omni的性能與Gemini-2.5-Pro和Qwen3-VL等模型不相上下。在VideoMME基準測試中,它在全模態模型中取得了最佳性能。
音頻能力中,研究人員主要評估了自動語音識別(ASR)、文本轉語音(TTS)和語音延續。
基礎模型在預訓練階段的ASR和TTS性能結果顯示,不同階段的基礎模型在上下文語音延續評估中表現良好,文本輸出和語音輸出之間的性能差異可以忽略不計。
在語音識別和翻譯、音頻理解、語音轉文本能力中,在所有模型中,LongCat-Flash-Omni的語音識別與翻譯測試集S2TT中表現最好最強;LongCat-Flash-Omni在沒有視覺輸入的情況下,能夠有效地作為原生音頻理解模型運行;在語音轉文本測試集中,LongCat-Flash-Omni在所有基準測試子集中均表現出色,并在多個案例中達到了最先進的水平。
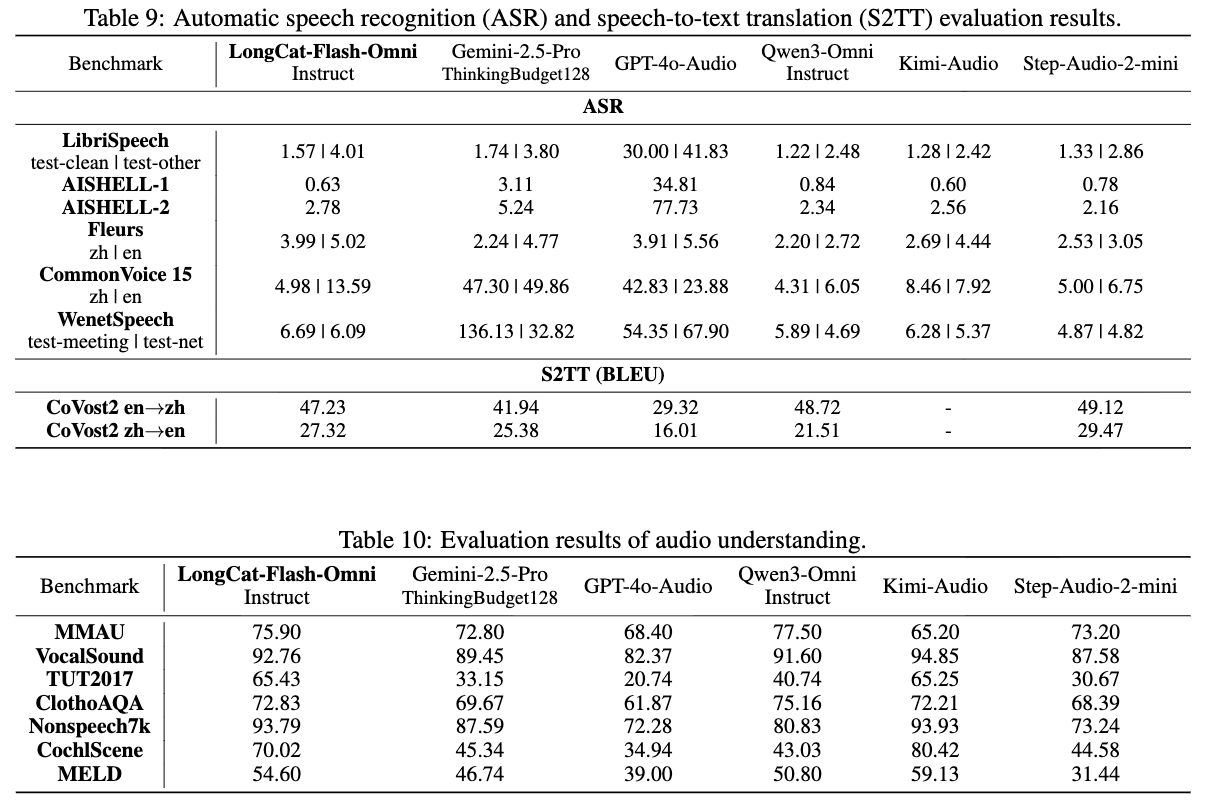
此外,LongCat-Flash-Omni還引入了高級跨模態理解和類人語音交互功能,能夠處理跨模態輸入。
評估結果顯示,LongCat-Flash-Omni的性能優于Gemini-2.5-Flash-non-thinking,并達到了與 Gemini-2.5-Pro-ThinkingBudget128相當的水平。
在強調真實世界音視頻理解的WorldSense和DailyOmni測試中,LongCat-Flash-Omni超越了其他開源全模態模型。在評估跨模態感知和推理能力的UNO-Bench測試中,LongCat-Flash-Omni在開源全模態模型中也表現出色。
實時音視頻交互的評估結果顯示,LongCat-Flash-Omni在端到端交互的自然度和流暢度方面得分排名第三。與音視頻交互產品相比,LongCat-Flash-Omni的排名低于豆包和GPT-4o,但優于科大訊飛星火和StepFun。
值得注意的是,LongCat-Flash-Omni在開源替代方案中得分比目前最先進的開源模型Qwen3-omni高出0.56分。
目前,LongCat支持音頻通話10分鐘,且響應很快,智東西讓其“講一個睡前小故事”,LongCat就實時生成并進行了講述。

二、劍指全模態大模型訓練四大挑戰,美團提出四大創新技術思路
訓練既具備強大的離線多模態理解能力又具備實時音視頻交互能力的全模態模型的挑戰性在于:
跨模態異構性指的是,不同模態之間存在顯著差異,因此需要探索有效的統一表征和融合策略,以實現跨模態的協同作用,確保任何單一模態的性能都不會低于同等規模的單模態對應模態。
統一的離線和流媒體能力,將離線多模態理解與流媒體音視頻交互相結合是一項重大挑戰,流媒體交互場景需要一些離線處理通常不具備的獨特能力,例如感知相對時間、精確同步音視頻信息以及高效管理多輪交互上下文。
實現實時音視頻交互本身就存在諸多難點,包括需要同時支持流媒體音頻和視頻輸入以及流媒體語音輸出,嚴格的低延遲要求進一步對計算效率提出了嚴格的限制,從而對模型架構設計和部署基礎設施都提出了很高的要求。
訓練效率挑戰,模型和數據的異構性給分布式策略的設計帶來巨大挑戰。
為克服第一個挑戰,研究人員設計了一個多階段大規模預訓練流程。基于早期文本預訓練基礎模型,他們逐步將音頻和視頻數據融入大規模預訓練過程,采用均衡的多模態數據混合和有效的早期融合策略,使得該模型在保持強大單模態性能的同時,實現跨模態的深度融合理解。
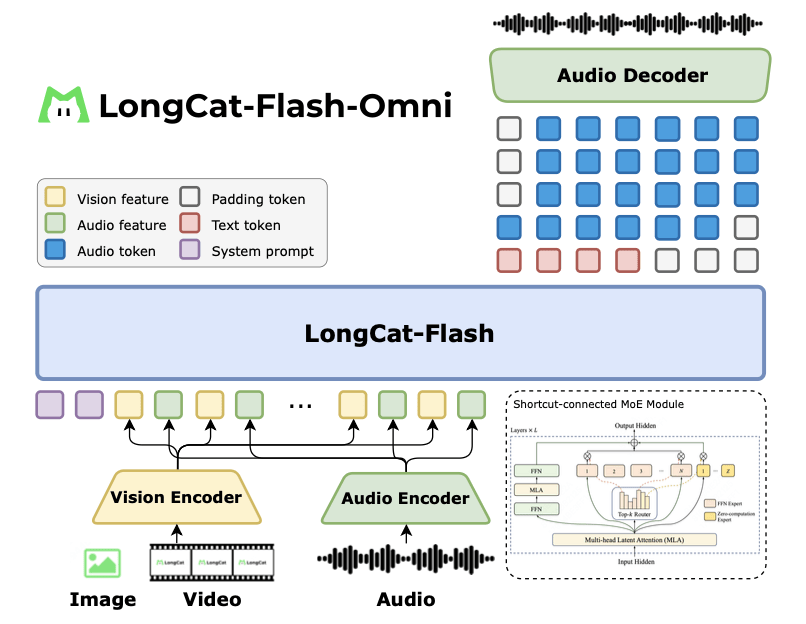
▲LongCat-Flash-Omni模型架構概覽
為了應對平衡離線多模態理解與實時音視頻交互的第二個挑戰,研究人員引入一種人機協同策略來構建高質量的交互數據,并考慮到長期記憶和多輪對話的處理。此外,其從現有的視覺文本語料庫中提取視覺語音問答數據,從而實現自然語音輸出,有助于將強大的離線多模態理解能力遷移到交互場景中。
對于第三個挑戰,研究人員采用ScMoE架構,并以LongCat-Flash的零計算專家作為大模型骨干。為了處理流式輸入,其采用高效的音頻和視頻編碼器進行特征提取,并引入同步分塊交錯策略以實現實時處理。
對于第四個挑戰,研究人員進行了大規模全模態分布式訓練,其提出一種模態解耦并行(MDP)策略。該方法能夠獨立優化大模型、視覺編碼器和音頻編碼器的性能和內存使用情況。
實驗結果表明了該策略的有效性,其系統能夠保持純文本訓練吞吐量的90%以上。
三、采用五階段漸進式訓練策略,借鑒LongCat-Flash訓練基礎設施
LongCat-Flash-Omni是一個端到端全模態模型,可以接收多種模態的輸入,包括文本、音頻、圖像、視頻及其任意組合,并能夠直接從大模型主干網生成語音token。
該模型采用視覺編碼器和音頻編碼器作為多模態感知器,大模型處理多模態輸入并生成文本和音頻token,音頻解碼器從大模型生成的語音token中重構波形,從而實現自然的語音交互。其中,音頻編碼器、視覺編碼器和音頻解碼器均為輕量級組件,每個組件的參數量約為6億個。
在預訓練階段,數據整理方面,研究人員收集了包含超過2.5萬億個詞元的大規模、多樣化的多模態語料庫用于預訓練。該預訓練語料庫由音頻數據、通用圖像-文本數據、視頻數據、OCR、長上下文多模態數據等部分組成。
訓練全模態模型最根本的挑戰之一在于不同模態間數據分布的顯著異質性,面對這一挑戰,研究人員采用了一種漸進式訓練策略,該策略逐步從簡單的序列建模任務過渡到更復雜的序列建模任務。
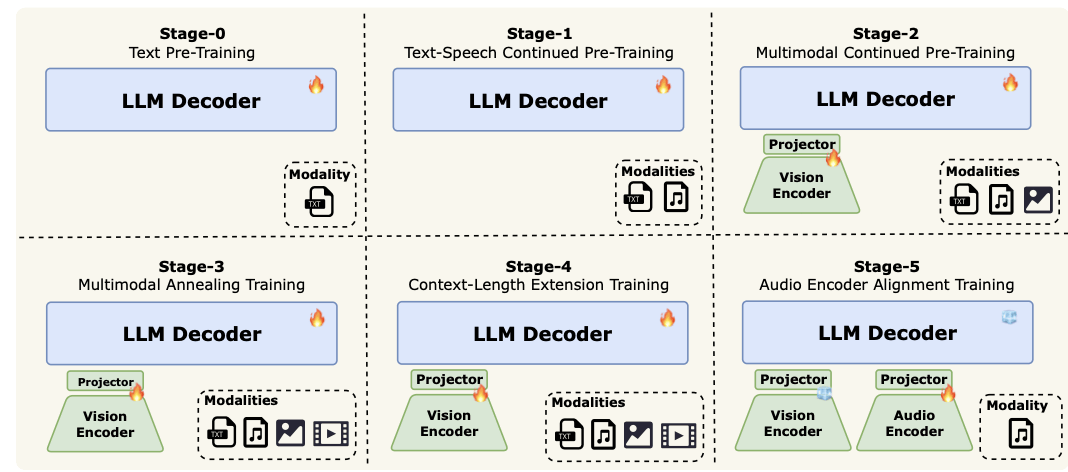
▲訓練策略
研究人員首先進行大規模文本預訓練(階段0),在此基礎上引入結構上更接近文本的語音數據,以將聲學表征與語言模型的特征空間對齊,并有效地整合副語言信息(階段1),語音-文本對齊完成后,其引入大規模圖像-描述對和視覺-語言交錯語料庫(階段2),以實現視覺-語言對齊,從而豐富模型的視覺知識。

▲預訓練階段1示意圖
然后,研究人員會引入最復雜的視頻數據以實現時空推理(階段3),同時整合更高質量、更多樣化的圖像數據集,以增強視覺理解能力。為了進一步支持長上下文推理和多輪交互,其將模型的上下文窗口從8K個詞元擴展到128K個詞元(階段4)。
最后,為了減少離散語音詞元表示的音頻輸入的信息損失,他們引入了一個音頻編碼器對齊階段(階段5),使模型能夠直接處理連續的音頻特征,從而提高下游語音任務的保真度。
在訓練后階段包含兩個組成部分:監督式微調、強化學習。
監督微調通過高質量且多樣化的指令數據賦予模型多模態指令遵循、推理和語音交互能力;強化學習通過直接偏好優化(DPO)進一步增強模型的行為一致性、連貫性和一致性。
在基礎設施方面,LongCat-Flash-Omni的核心設計原則借鑒了LongCat-Flash開發過程中使用的訓練基礎設施,為了保證數值一致性,研究人員強制執行確定性、最小化誤差并保持誤差的可解釋性,從而確保每次訓練運行都具有確定性和可復現性。為了提高效率,他們將大模型、視覺編碼器和音頻編碼器的各個組件解耦,從而可以獨立優化它們的性能和內存使用情況。
實驗結果表明,在多模態環境下,他們的系統能夠保持純文本訓練90%以上的吞吐量。
推理與部署時,研究人員提出解耦的多模態推理框架,該框架將特定模態的編碼器/解碼器與層級模型分離,以實現優化部署。每個模塊都部署在與其計算特性相匹配的專用硬件和加速器上,從而緩解跨模態資源爭用。
其還采用異步流式模型服務管道,每個模塊都支持流式輸入的增量推理和自適應批處理策略,從而實現并發調度以降低延遲。
結語:未來要探索更豐富的具身智能交互形式
大量評估表明,LongCat-Flash-Omni不僅在Omni-Bench和WorldSense等全模態基準測試中取得了最先進的性能,而且在圖像和視頻理解以及音頻理解等關鍵單模態任務中,其性能也與閉源系統持平甚至更優。此外,主觀評估證實了該模型能夠提供自然、低延遲、高質量的交互體驗,凸顯了其作為下一代人機交互界面基礎的巨大潛力。
研究人員提到,基于LongCat-Flash-Omni,他們未來的工作將著重于擴展訓練數據的多樣性和規模、整合自適應思維模式、完善流式傳輸和生成能力,并探索更豐富的具身智能和交互智能形式。他們相信,LongCat-Flash-Omni的發布不僅將加速多模態理解和生成的研究,還將啟發構建以人為本、面向通用人工智能系統的新應用和新范式。
- 1024程序員節京東開放“零幀起手”數字人技術
- 限時一口價20.69萬起,后驅豪華轎車上市新配色,顏值拉滿
- 孫穎莎王楚欽混團世界杯開門紅
- 國考今日開考 平均競爭比98比1
- 《瘋狂動物城2》成為進口動畫票房冠軍
- 羽絨服大漲價是什么情況
- 周潤發時隔十年給權志龍頒獎
- 6G技術重大突破!萬億元級市場來了
- 鄉村產業繼續保持良好發展勢頭
- 新款藍電E5 PLUS來了!限時11.98萬,純電續航230公里,配FSD懸架
- 吉利豪越L中型SUV煥新登場,限時8.99萬起,大空間多座可選還配雙動力
- 12月車市盛宴來襲!6款熱門轎車扎堆上市 新款卡羅拉等重磅登場
- 9.78萬起的零跑Lafa5上市 搭載雙AI大模型與激光雷達
- 豐田GR GT跑車12月5日全球首發,大排量混動超跑劍指德系勁敵
- 捷尼賽思GV90或推雙版本車門布局 旗艦級純電SUV預計2026年末亮相
- 新款問界M7無偽諜照曝光!采用全新家族式前臉,尾部造型更精致
- 卡樂馳CARLOCS:都說新車別貼隱形車衣,到底是為什么?
- 長安福特新蒙迪歐12月4日上市:全新進氣格柵、隱藏式門把手
- 北京汽車制造廠212 T01混動版發布,外觀復古硬朗,明年一季度上市
- 銀河航天徐鳴:太空基建加速跑 6G通信與新場景引領產業新變革