1米3的機器人小土豆,三步上籃也可以如此絲滑。
別誤會,這臺宇樹G1暫時還不準備參加NBA選秀,但它剛解鎖的 “現實世界打籃球” 技能,離上“村BA”首發應該不遠了。
據悉,這是全球首個能在真實場景中完成籃球動作的機器人demo,來自香港科技大學的研究團隊。
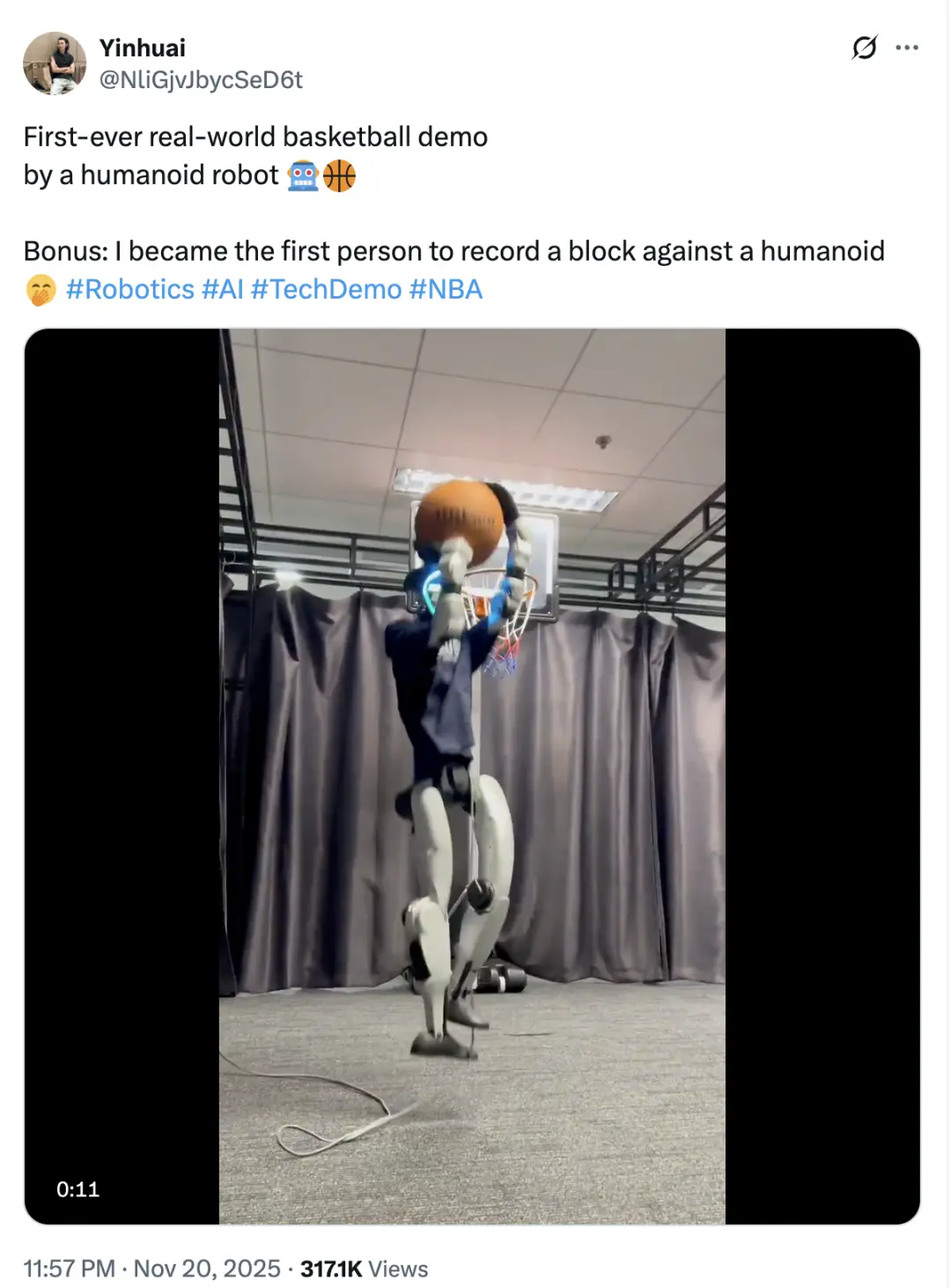
雖然團隊還沒公開完整的技術細節,但結合他們此前讓機器人“打籃球”的工作,這次很可能是在之前研究的基礎上,進一步改良而來。
接下來,讓我們一窺究竟。
SkillMimic-v2
首先是被收錄于SIGGRAPH 2025的SkillMimic-V2: Learning Robust and Generalizable Interaction Skills from Sparse and Noisy Demonstrations。

SkillMimic-V2旨在解決交互演示強化學習(RLID)中演示軌跡稀疏、含噪且覆蓋不足的難題。
其通過引入拼接軌跡圖(STG)與狀態轉移場(STF)、自適應軌跡采樣(ATS)等技術,成功地在低質量數據條件下,訓練出了兼具魯棒恢復能力與技能遷移能力的復雜交互策略 。
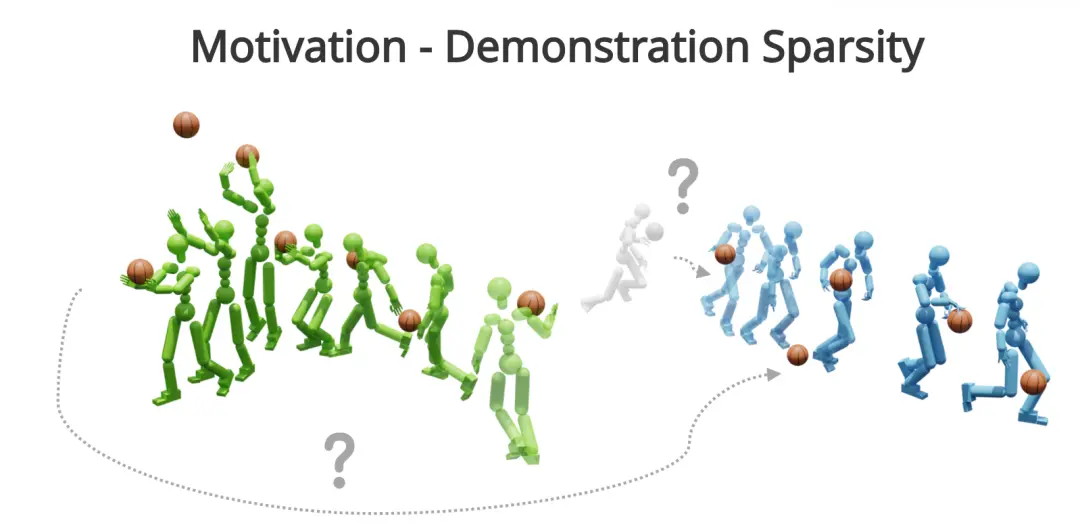
當前,通過動作捕捉等方式收集的數據往往存在以下缺陷:
稀疏性 (Sparse):演示數據僅覆蓋了有限的技能變體,缺乏技能之間的過渡軌跡。
不連貫性 (Disconnected):不同的技能片段是獨立的,缺乏自然的連接。
噪聲 (Noisy):數據中包含物理上不可行的狀態或誤差(例如手與物體的穿模、接觸位置偏差),這在精細操作任務中會導致嚴重的訓練失敗。
這些有缺陷的數據無法捕捉到技能變體和轉換的完整頻譜。
不過,相比直接去收集更好的數據,研究認為盡管演示數據是稀疏和嘈雜的,但存在無限的物理可行軌跡 。
這些潛在的軌跡天然地能夠橋接不同的技能,或者從演示狀態的鄰域中涌現出來。
這就形成了一個連續的、可能的技能變體和轉換空間,從而可以利用這些不完美的演示數據,訓練出平滑、魯棒的策略。
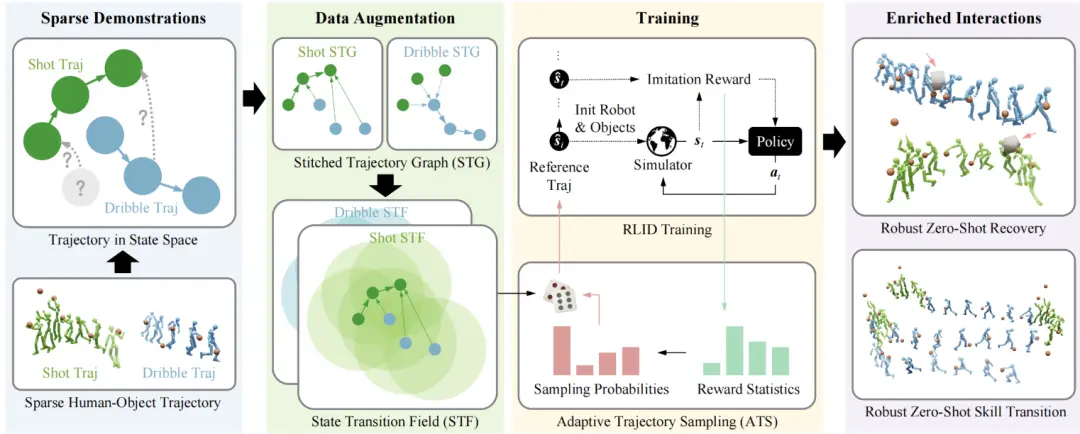
基于以上認識,研究提出三個關鍵步驟發現并學習這些潛在軌跡:
拼接軌跡圖 (Stitched Trajectory Graph, STG):為了解決技能間的連接問題(如從運球切換到投籃),算法在不同演示軌跡之間尋找相似狀態。如果在兩個不同技能的軌跡中發現相似狀態,就建立一條連接,并用掩碼標記中間的過渡幀。這構建了一個宏觀的圖結構,允許策略學習未在原始數據中出現的技能轉換。
狀態轉移場 (State Transition Field, STF):訓練時不只從參考軌跡的特定點開始,而是從其鄰域內隨機采樣狀態初始化。對于鄰域內的任意采樣狀態,計算其與參考軌跡中所有狀態的相似度,找到最佳匹配目標。如果起點與目標點距離較遠,算法會插入N個掩碼狀態(Masked States)。這些狀態不計算獎勵,僅作為時間緩沖,迫使RL策略學習如何從偏離狀態“歸位”到參考軌跡,從而形成一個具有恢復能力的“場” 。
自適應軌跡采樣 (Adaptive Trajectory Sampling, ATS):根據當前策略在某段軌跡上的表現(獎勵值)動態調整采樣概率。獎勵越低(越難學)的片段,被采樣的概率越高。這解決了長序列中因局部失敗導致整個鏈條斷裂的問題。
由此,技能轉換和泛化能力能夠遠超最初不包含任何技能轉換或錯誤恢復的稀疏演示,實現更高效地技能學習與泛化性。
比如,在仿真環境(Isaac Gym)中,機器人可以在受到干擾時,仍可以完成上籃動作。
還能實現運球-投籃間的技能轉換。
實驗表明,相比此前的SOTA (SkillMimic)方法,SkillMimic-V2在困難技能(如 Layup)上的成功率從0提升到了91.5%。技能轉換成功率 (TSR) 更是從2.1%飆升至94.9%。

SkillMimic
接下來是SkillMimic-V2的前作——SkillMimic: Learning Basketball Interaction Skills from Demonstrations,這篇論文入選了CVPR 2025 Highlight。

SkillMimic旨在解決物理模擬人-物交互(HOI)中傳統方法依賴繁瑣手工獎勵設計且難以在統一框架下掌握多樣化技能的難題。
其通過引入統一HOI模仿獎勵與接觸圖(Contact Graph)、分層技能復用等技術,成功地在單一獎勵配置下,訓練出了兼具精準接觸控制與長程任務組合能力的通用交互策略。
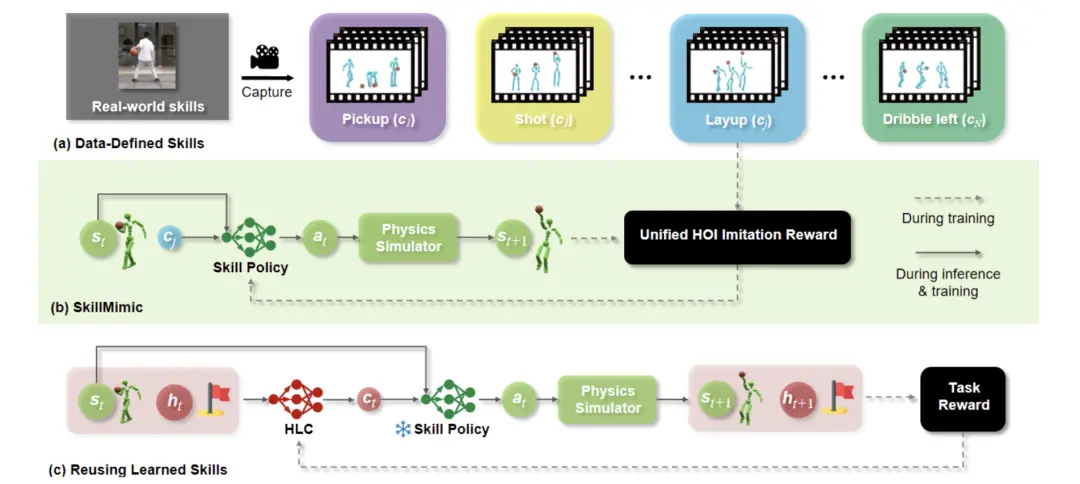
研究pipeline包含三個部分:
首先,采集真實籃球運動技能,構建一個龐大的人機交互(HOI)運動數據集。
其次,訓練一個技能策略,通過模仿相應的HOI數據來學習交互技能,設計了一個統一的HOI模仿獎勵機制,用于模仿各種不同的HOI狀態轉換。
最后,是訓練一個高級控制器(HLC),用于復用已學習的技能來處理復雜任務,同時使用極其簡單的任務獎勵。
其中,SkillMimic方法的關鍵在于:
統一的HOI模仿獎勵(Unified HOI Imitation Reward):放棄針對每種技能單獨設計獎勵,而是設計一套通用的獎勵配置,通過模仿HOI數據集來學習所有技能 。
分層學習架構(Hierarchical Solution):低層:交互技能策略(IS Policy):通過SkillMimic框架學習各種基礎交互技能(如運球、上籃)。高層:高級控制器(HLC):訓練一個高級策略來復用和組合已習得的IS策略,以完成長程復雜任務(如連續得分)。
數據驅動:構建了兩個數據集BallPlay-V(基于視頻估算)和BallPlay-M(基于光學動捕,精度更高),包含約35分鐘的多樣化籃球交互數據 。
實驗表明,SkillMimic能夠使用同一套配置學會多種風格的籃球技能(運球、上籃、投籃等),成功率顯著高于DeepMimic和AMP。
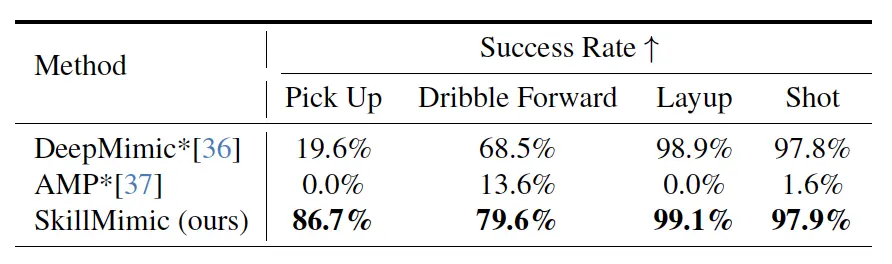
在演示中,我們可以看到,仿真環境的機器人能夠實現繞圈運球等高級技能。
PhysHOI
如果追溯SkillMimic作者的工作,就會發現早在2023年,論文PhysHOI: Physics-Based Imitation of Dynamic Human-Object Interaction就試圖讓仿真中的機器人能夠根據演示學習籃球技能。
為實現這一點,PhysHOI在當時提出了一種基于物理仿真的動態人-物交互(HOI)模仿學習框架。
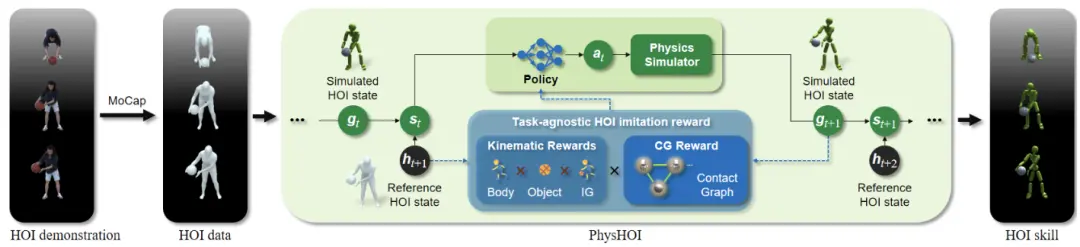
簡單來說,給定參考的HOI數據,將當前的模擬HOI狀態與參考HOI狀態一起輸入策略模型。
策略輸出動作,并通過物理模擬器生成下一步的模擬HOI狀態,然后將運動學獎勵與接觸-抓取(CG)獎勵加權結合,并優化策略以最大化期望回報。
重復上述過程直至收斂,即可復現參考數據中的HOI技能。
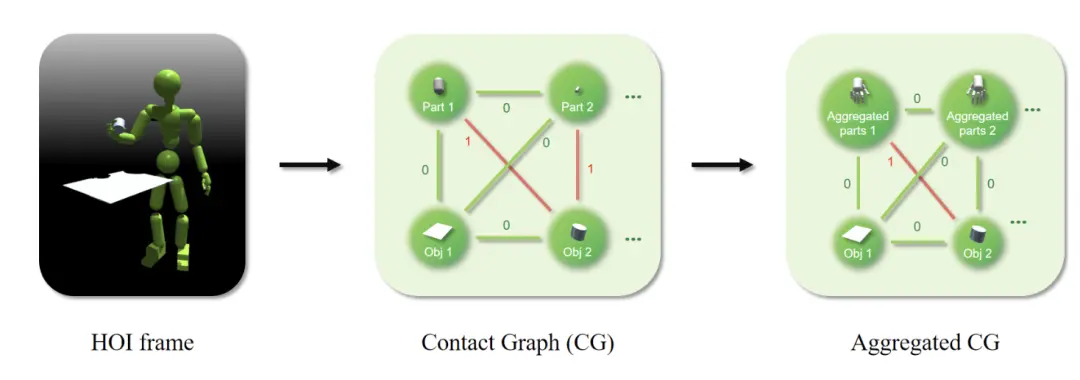
除此之外,為防止運動學模仿獎勵陷入最優解,研究還引入了接觸圖(Contact Graph)——
給定一個HOI幀,接觸圖節點包含所有身體部位和物體。每條邊都是一個二元接觸標簽,表示接觸與否。為了簡化計算,還可以將多個身體部位聚合到一個節點中,形成聚合接觸圖。
同時,為了彌補HOI場景的不足,研究還引入了全身籃球技巧的BallPlay數據集。

在實驗中,PhysHOI在不同大小的籃球操作上表現出了魯棒性。
One more thing
值得一提的是,在PhysHOI、SkillMimic 、SkillMimic-v2三篇工作中,王蔭槐都擔任了核心角色,網友調侃他是“籃球科研第一人”。

王蔭槐是香港科技大學的博士二年級學生,導師為譚平教授。
在此之前,他碩士就讀于北京大學,本科畢業于西安電子科技大學,并于IDEA Research、宇樹科技以及上海人工智能實驗室等機構進行實習。
從2023年在仿真環境的小試牛刀,到這次直接讓機器人在真實環境中打球,得益于機器人本體的發展,這速度真是很快了!

- 1024程序員節京東開放“零幀起手”數字人技術
- 內置24000轉/分鐘風扇!紅魔11 Pro圖賞
- W47單品銷量,小米17 Pro Max真牛,同檔國產全沒上榜
- 紅魔11 Air證件照公布:驍龍8至尊版、7000mAh電池
- 貝爾金發布70W氮化鎵三口快充頭,售316元
- 英特爾Nova Lake曝光:旗艦52核怪獸,性能核IPC漲15%
- 一張圖看懂智駕"安全公開課"嘉賓精彩觀點
- 靈隱寺免門票首日入園名額已約滿
- 黃河壺口瀑布現“彩虹橫臥”景觀
- 兩個“1980” 蘇翊鳴強勢奪金
- 男子花1年定制2米高可通話摩托羅拉
- 長沙連續17年獲中國最具幸福感城市
- 劉強東:未來機器人會完成所有工作
- 300元滑雪服被凍哭的年輕人焊身上了
- 退休老人不搶雞蛋搶起了船票
- 大腦“斷崖式衰老”的3個年齡
- 老君山景區拒絕用無人機取代挑山工
- 解讀智己LS9,標配520線激光雷達+Thor芯片,究竟有啥不同?
- 聯想提出RNL技術,通過多維感知等解決AI訓練中的難題
- 曝特斯拉曾拆解多款中國電動汽車